 Ramón López de Mantaras, director del IIIA.CSIC, impartiendo una conferencia. Foto. Adolfo Plasencia.
Ramón López de Mantaras, director del IIIA.CSIC, impartiendo una conferencia. Foto. Adolfo Plasencia.
“No creo en la ‘exponencialidad’ del progreso de la técnica y la tecnología. Esto es falso. No progresan exponencialmente.”
UNA CONVERSACIÓN EN PROFUNDIDAD CON RAMÓN LÓPEZ DE MÁNTARAS, SOBRE LA INTELIGENCIA ARTIFICIAL.
Por: Adolfo Plasencia.
El actual momento de la Inteligencia Artificial.
Parte I. SOBRE LOS ‘PRINCIPIOS’ DE LA AI
Según en diccionario de la RAE, la expresión ‘inteligencia artificial’ es un término de Informática cuyo significado es: “Disciplina científica que se ocupa de crear programas informáticos que ejecutan operaciones comparables a las que realiza la mente humana, como el aprendizaje o el razonamiento lógico”. Según Wikipedia, La inteligencia artificial (IA) es un área multidisciplinaria, que a través de ciencias como las ciencias de la computación, la matemática, la lógica y la filosofía, estudia la creación y diseño de sistemas capaces de resolver problemas cotidianos por sí mismas utilizando como paradigma la inteligencia humana.
La actual explosión de aplicaciones prácticas para la Inteligencia artificial (AI) es la consecuencia, al menos de varios factores combinados tras un largo periodo en el que parecía que la disciplina había quedado como aletargada después de que el la época de los años 90 se vieron avances espectaculares. Las causas de esta explosión podrían estar en varios factores de cambio combinados a mi modesto entender. Por supuesto en primer lugar en el avance continuado de la Ley de Moore que ha seguido aumentando la capacidad de computación de todos los dispositivos digitales al tiempo que hacían la capacidad de cálculo mucho mas baratas, lo que ha dado lugar a que pequeños dispositivos sean capaces de procesar cantidades antes impensables. Por ejemplo los smarphones avanzados, mas potentes que la mayoría de los grandes ordenadores de sobremesa de la Era del PC. El segundo factor es el cambio de paradigma de la informática que parece haber dado la vuelta a una esquina para abrirse a la era post-PC como la definió Steve Jobs poco antes de dejarnos. En la Era Post-PC, gracias a los Data Centers y las ‘granjas de Servidores’ y, obviamente a Internet, disponemos de una inmensa capacidad de cómputo que podemos situar en forma ubicua (en cualquier momento y cualquier lugar) para propósitos concretos que serían irrealizables. Y el tercer factor y no menos importante es el trabajo incansable y callado de investigadores muy especiales que se han centrado durante muchos años en avanzar en aspectos decisivos de la Inteligencia Artificial que permitieran usar aspectos de esta disciplina en la práctica. Uno de ellos es Ramón López de Mántaras, que actualmente dirige el Instituto de Investigación en Inteligencia Artificial (IIIA), del CSIC, que ha realizado numerosos avances en la investigación de la creatividad computacional, entre otros, en campos como los de la música. He conversado con él para comentar ‘el estado del arte’ en esta fase de enrome expansión actual de la Inteligencia Artificial. Esta ha sido la conversación:
ADOLFO PLASENCIA: Ramón, para alguien como tú, que tienes formación en Ingeniería eléctrica, física, diriges el Instituto de Inteligencia Artificial del CSIC y eres Premio Nacional de Informática 2012, ¿La Inteligencia Artificial, es un tema de ciencias de la computación, o como dice Wikipedia, va mas allá y para ti llega hasta las humanidades?
RAMÓN LÓPEZ DE MÁNTARAS: Yo pienso que va mas allá de la informática, de la Computer Science para se llama en EE.UU., y efectivamente llega hasta las humanidades. No sólo a nivel de las aplicaciones. Obviamente existan ya aplicaciones para la simulación de grandes agentes y entes sociales, que tiene que ver con temas de sociología. Tiene que ver con la economía porque la Teoría de Juegos se utiliza mucho en Inteligencia Artificial (AI). Y para las aplicaciones en esta campo nos inspiramos en mucha otras ciencias. La Inteligencia Artificial, no es ahora una tecnología o una ciencia vertical, es muy ‘horizontal’, como las matemáticas por ejemplo. Sirve para modelar, modelizar muchas cosas.
A.P.: ¿Y se inspira de la filosofía, también, ¿no?
R.L.M.: También de la filosofía, claro. Hay muchos filósofos de la ciencia contribuyendo como Daniel Dennet o John Searle, por ejemplo, que son muy críticos con la AI, pero eso está bien porque así hay diálogo y discusión y, de ello salen nuevas ideas. Como te decía, la Inteligencia Artificial es una herramienta muy buena para modelizar computacionalmente fenómenos complejos y en particular la actividad cognitiva. La cognición, y la inteligencia es un fenómeno muy complejo, que nadie sabe muy bien aún qué es, pero que sabemos que está ahí, que emerge del cerebro y que permite tomar decisiones racionales, o no, y también emocionales. Ya sabemos por los trabajos de Antonio Damasio que es necesaria la capacidad emotiva para tomar decisiones. Si fueras cien por cien racional no llegarías nunca a tomar ninguna decisión. O sea que hay muchos ‘va y viene’ entre la AI y otras disciplinas. Actualmente es mucho mas que informática y, en mi opinión, la gente que se forma para AI no solo deben saber de programar y saber matemáticos sino muchas otras cosas una formación mas pluridisciplinar en los niveles avanzados. Deberían conocer cosas, por ejemplo, cosas sobre psicología cognitiva, lingüística, etc. Hay un término: ‘cognitive sciences’ que intenta englobar todas estas áreas que tienen en común el estudio del comportamiento inteligente y de la cognición desde distintos puntos de vista. Hay nuevas sinergias claras que nos permitirán avanzar en Inteligencia Artificial y en modelizar la cognición humana.
A.P.: ¿Ramón, Estás mas por el paradigma de la inteligencia artificial que parte del modelo de la imitación de la inteligencia humana o crees que no siempre es necesario partir de ese principio y se puede crear una inteligencia artificial partiendo de un paradigma distinto?
R.L.M.: Ya estamos haciendo inteligencia artificial que no tiene nada que ver con el emular o imitar a nivel detallado a la inteligencia humana. Hay las dos vías en la AI. Los aviones no vuelan batiendo las alas, porque no han imitado exactamente a la naturaleza, pero se han inspirado en ella. Una cosa es imitar y otra inspirarse. El referente es la inteligencia humana. Siempre. De eso no hay duda. Ahora, tú puedes llegar a soluciones distintas a las que ha llegado la naturaleza para resolver ciertos problemas. El problema de volar, de que un artefacto que pesa mas que el aire vuele, primero lo resolvimos con la propulsión de las hélices y luego mediante el motor a reacción a chorro. Pero el construir aviones con esos sistema contribuyó a que progresara la aerodinámica y con ello, después, pudimos explicar porqué los pájaros vuelan. De nuevo vemos un ‘va y viene’. Yo creo que en la inteligencia artificial puede pasar lo mismo. Hay modelos computacionales que se han desarrollado no necesariamente imitando a nivel de detalle las neuronas del cerebro, sino que se han hecho de forma distinta y después esto puede arrojar alguna luz sobre cómo pueden funcionar los proceso mentales en el cerebro, o viceversa. Cuando hacemos razonamiento basado en casos, que es un área de la AI muy interesante que trata de cosas como aprender o razonar por analogía, reconociendo similitudes entre situaciones, que es algo muy bien fundado y tiene muchas bases cognitivas, nos damos cuenta de que los humanos hacemos mucho esto. Tenemos un problema a resolver y vemos se parece a uno que ya hemos resuelto, y utilizamos las soluciones anteriores, adaptándolas, para resolver el nuevo problema. Casi es de sentido común que sea así. Se ha conseguido hacer con ordenadores, con máquinas que hacen razonamiento por analogía basado en casos y cuando lo hemos resuelto, esto a su vez, posteriormente, hemos comprobado que arroja luz sobre cómo lo hace el cerebro humano. El concepto de similitud y todos esto. Yo diría en resumen que la Inteligencia Artificial, más que imitar al detalle la inteligencia del cerebro, ‘se inspira’ en el funcionamiento del cerebro pero para hacerlo, quizás, de otra manera. Bueno, a excepción de algunos proyectos como, por ejemplo el Blue Brain y otros que van por el camino de intentar emula lo que se hace desde cada neurona, sobre lo que tengo una opinión muy critica al respecto.
A.P.: Marvin Minsky, afirmó que crear una inteligencia no es tan complicado: según la teoría de Marvin Minsky de que un principio de inteligencia puede construir comenzando por un conjunto bastante simple de primitivos y que al conectividad entre ellos es la que da como resultado la complejidad que surge y se deriva una conducta, y que tiene que ver con la toma de decisiones, de la que en caso extremos puede depender la supervivencia. Minsky piensa que a inteligencia no procede de un mecanismo único, sino que se genera por la interacción de muchos agentes distintos. Y en su libro ‘La máquina de las emociones’ atribuye ese origen múltiple también a las emociones, los sentimientos y el pensamiento consciente. ¿Que opinas de esta visión de Minsky?
R.L.M.: Yo estoy de acuerdo con él, en la parte esta de que la inteligencia no es el resultado de un mecanismo único y que se genera por interacción de muchos agentes distintos. Todo eso está basado en la teoría de su libro ‘The Society of Mind‘. En el fondo lo que está diciendo es que la inteligencia emerge de interacciones de agentes muy simples (él piensa que son ‘muy simples’), y al interaccionar entre ellos, la colectividad produce la inteligencia. Es como la idea de la inteligencia de las colonias de hormigas. Cada una de ellas no es inteligente pero la colonia globalmente hace cosas inteligentes. Pero Minsky va mas allá de esto. Habla de una arquitectura cognitiva basada en una Sociedad de la mente, una sociedad, -en sentido metafórico-, de ‘agentes’ de la mente en el cerebro y que de ahí emerge la inteligencia. Yo no veo ningún problema en esta afirmaciones de Minsky, pero lo que no me ha dicho ni él ni nadie, hasta ahora es cómo construimos esto, cómo lo reproducimos. En su libro, no nos dice cómo podemos implementar eso en una máquina. Se queda en un nivel filosófico, pero no llega al cómo hacerlo.
A. P.: Hablemos ahora, en relación a esa conexión masiva de la que hablaba Minsky, pero referida a la ‘maquinaria’ del cerebro que es de al que se supone que emerge al inteligencia humana. Kenneth D. Miller, profesor de neurociencia en Columbia y co-director del Centro para la Neurociencia Teórica, publicó no hace mucho en el New York Times un artículo titulado: “Will You Ever Be Able to Upload Your Brain?“. En él afirma muy critico sobre las pretensiones de algunos grandes proyectos actuales. En su articulo escribe: “Gran parte de la esperanza actual de la reconstrucción de un funcionamiento del cerebro descansa sobre conectómica: la ambición de construir un diagrama de ‘cableado completo’ [en el sentido de la metáfora informática ], o “conectoma,” de todas las conexiones sinápticas entre neuronas en el cerebro de los mamíferos. Desafortunadamente, la conectómica, mientras que una parte importante de la investigación básica. Yo creo que está muy lejos de la meta de la reconstrucción de una mente, en dos aspectos. En primer lugar, estamos muy lejos de construir un conectoma. El actual mejor logro fue determinante las conexiones en un pequeño trozo de tejido cerebral que contiene 1.700 sinapsis; el cerebro humano tiene más de cien mil millones de veces ese número de sinapsis. Si bien el progreso es rápido, nadie tiene ninguna estimación realista de cuánto tiempo se tardará en llegar a conectomas cerebro de tamaño”. Mi conjetura ‘salvaje’ -dice Miller-, es que replicar un conectoma como el del cerebro es algo que llevaría una escala de tiempo de siglos. Teniendo en cuenta que no eres neurofisiólogo, sino ingeniero y informático. ¿Crees que lo del ‘Uplooad’ de una inteligencia, que menciona se quedará Miller, seguirá siendo cosa de literatura, cine o ficción? ¿Crees que una inteligencia de la escala de la humana se podría reubicar, ‘subir’ o ‘descargar’, o eso no es posible ni siquiera en teoría?
R.L.M.: para mi lo del hacer un ‘Uplooad’ de una inteligencia, descargarla, llevarla a otro lugar, es una pura ciencia ficción. Y no solo para mí, sino para varios premios Nobel de Biología y Bio-medicina. Eso estar relacionado con lo de la Singularidad…
A.P. … de la que tanto ha escrito Ray Kurzweil, hoy director de Ingeniería de Google…
R.L.M.:… que hablan de que el ‘upload’ del cerebro en una máquina, y luego la sinergia entre este ‘upload’ y la propia inteligencia artificial de a máquina sería un conjunto que permitirá crear superinteligencias. El problema de mucha de esta gente es que subestiman la complejidad del cerebro. Del cerebro se sabe más que antes, pero aun sabemos muy poco. Todo esto parte conocer y modelizar la parte eléctrica de las neuronas. Las neuronas tienen un parte química, están, funcionan, sumergidas en una ‘sopa’ de química. Y todo esto, ningún modelo computacional de redes neuronales tiene en cuenta eso, ninguno. Además, hasta hace poco no se sabía que las células llamadas ‘gliales’ del cerebro son como un ‘metacontrol’, controlan lo que hacen las neuronas y son más numerosas en que las neuronas. Fíjate, hay mas células ‘gliales’ que neuronas en el cerebro. Y controlan las sinapsis, la conexiones entre neuronas. Ahora los biólogos creen que estas células tienen un papel importantísimo en el funcionamiento del cerebro. Y ningún modelo computacional de redes neurales tiene en cuenta esto ni lo modeliza. Y tampoco lo tienen en cuenta los modelos de mapas de conexiones de la conectómica. La parte química del cerebro no se ‘modeliza’. Por tanto, ¿qué significa hacer un ‘upload’ de un cerebro? ¿Qué van a ‘descargar? ¿El estado eléctrico de cada neurona? No son estados discretos (como en lo digital). Hay muchas cosas que son de procesamiento continuo, de nivel analógico, no tanto digital, en el cerebro. ¿Que significa hacer un upload? ¿hacer una ‘foto’ de un instante del cerebro y cargar eso?¿Y luego qué? ¿El siguiente instante qué; aquello de queda fijo? ¿Y las experiencias de toda tu vida? porque esas también están en algún lugar del cerebro, pero nos e sabe cómo están almacenadas ni nada. Para mí tiene muy poco sentido esto que dicen de hacer un ‘upload’ de un cerebro. Cualquier biólogo te dirá que esto no tiene sentido y que esa idea es pura ciencia-ficción. Nuestro cerebro es en cada instante distinto.
A.P.: Michail Bletsas me ha dicho que él esta seguro que a lo largo de este siglo surgirá una inteligencia no-biológica, o no basada en el homo-sapiens. La astrofísica Sara Seager, especialista en exoplanetas, a su vez me ha dicho que lo mas probable es que mas allá del sistema solar, es que la inteligencia actúe en formas ‘no-biológicas’”. Teniendo en cuenta la evolución actual de la tecnología, si te pido que intentes imaginar una inteligencia no-biológica, ¿cuál es lo primer camino que viene a tu imaginación? ¿Cómo imaginas que podría ser en el largo plazo, la AI?
R.L.M.: En la inteligencia artificial que tenemos hoy en día está la ‘AI débil’, de la que hablaba yo ayer, y también de la que habla Thomas G. Dietterich, que funciona cómo herramienta que nos ayuda a tomar decisiones, pero que no tiene porqué tener ‘estados mentales’ ni nada de eso sino que es una visión muy práctica de la AI es una inteligencia no-biológica. está basa en el silicio y los ordenadores no son biológicos actualmente ¿no? Ya sabemos hacer inteligencia no-biológica. Ahora, … elucubrar sobre cómo será en el futuro la AI no-biológica, si estará en algo distinto del silicio. Pues sí, muy probablemente. Los ordenadores basados en silicio va a ser reemplazados, porque sabemos que la Ley de More esta llegando a un límite, así que si se quiere seguir aumentando la capacidad de los ordenadores habrá que cambiar de tecnología. Habrá hardware distinto para hacer cálculos. Hay varias tecnologías posibles de las que se habla, basadas en memristores, o en el DNA computing, en computación cuántica, hay muchas propuesta ya por ahí. A largo plazo no tengo ni idea pero es muy probable que tanto la computación como la futura AI, deje de estar basada en el silicio.
Parte II. SOBRE LAS MÁQUINAS INTELIGENTES
A.P.: El de las ‘máquinas inteligentes’ es uno de los paradigmas mas atractivos de la tecnología y en los humanos asociamos inteligencia y mente con el cerebro. Bertrand Russel afirmó que la diferencia entre mente y cerebro no es una diferencia de cualidad sino de ‘disposición’. ¿Tu crees que la inteligencia en una máquina que lo sea, dependerá mas esencialmente de una masa crítica de capacidad de calculo (computación) o de la combinatoria y disposición o combinación de partes, recursos y mecanismos, a imitación, por ejemplo, de la disposición de un cerebro?.
R.L.M.: Creo que dependerá un poco de todo. Ahora mismo, el Machine Learning (el aprendizaje o razonamiento automático) está dando un buen paso adelante en cuanto a aplicaciones prácticas aunque en lo conceptual no hay nada nuevo. Lo que hay es que con la disponibilidad, al tiempo, computación de altas prestaciones en y del acceso a enormes cantidades de datos (Big Data), se pueden hacer cosas que hace veinte años no se podían hacer por no disponer de ello. pero los conceptos que hay detrás del Deep Learning (Aprendizaje profundo) ya existían hace veinte años lo que pasa es que ahora se pueden aplicar en la práctica. Así que lo que se pueda hacer con la futura AI, creo que dependerá a la vez de la capacidad de cálculo tanto como del software y de la combinación de los distintos componentes de la inteligencia, de su integración, de las arquitecturas cognitivas que integren razonamiento con aprendizaje y con planificación, etc. Aunque no sepamos aún qué es la inteligencia lo que si sabemos son cuáles son algunos de sus componentes: capacidad de percibir, de comunicar, de razonar, de planificar, de aprender… Los componentes de la inteligencia habrá que combinarlos de forma conveniente mediante una buena arquitectura. Necesitamos buenos arquitectos cognitivos que nos digan cómo conectar estos componentes de la inteligencia. La disposición de estos componentes es importante y la capacidad de cálculo también. Es la combinación de ambas cosas, creo yo.
 Robots en el MIT Media Lab. Foto: Adolfo Plasencia
Robots en el MIT Media Lab. Foto: Adolfo Plasencia
Parte III. AI Y ROBÓTICA
A.P.: Volvamos a lo de la disciplina de la AI. En tu conferencia has hablado sobre que, en la AI, tras una época de grandes expectativas, hubo un parón o un ‘invierno’ en la ciencia de la Inteligencia Artificial’. Rodney Brooks, que ha dirigió casi 18 años el “Computer Science and Artificial Intelligence Laboratory (CSAIL)”, del MIT me dijo que él prefería dejar las ‘grandes preguntas’ de la AI para la siguiente generación de científicos. Hoy, tras abandonar la investigación académica como centro de su actividad, lanzó con la empresa iRobot el exitoso robot de limpieza Roomba; ahora dirige su nueva empresas Rethink Robotics, especializada en ‘collaborative robotics’.
Tú también llevas muchos años en el campo de la AI. ¿A ti no te afectó ese ‘invierno’ de la AI.? ¿Ya ha cambiado de ‘estación’? ¿Hay ahora una nueva primavera en la AI?
Y también: ¿No has tenido tentaciones de irte al sector empresarial en donde aplicar lo adquirido e tu larga experiencia de investigador en AI?
R.L.M.: Sí, hay una nueva primavera, sin duda. Bueno, a ver. Yo empecé a trabajar en AI en el año 76. Y el ‘invierno de la AI’ llegó justo después, pero yo era entonces un joven estudiante. Luego estuve en Berkeley aprendiendo más sobre Inteligencia Artificial, después hice mi tesis en Francia. En aquél momento yo todavía no dirigía un equipo de investigación, no me tenía que preocupar por captar recursos para la investigación como sí tenían que hacerlo mis ‘seniors’, mis supervisores en EE.UU. que sí que recuerdo que tenían problemas a la hora de conseguirlos. A mí personalmente no me afectó. Ya en España no afectó porque el ‘invierno’ era aquí lo normal en la AI. Era un desierto. En los Congresos y reuniones internacionales recuerdo que si que había esa sensación con colegas. Lo que sí puedo decirte que sí ha cambiado la estación de la AI en el mundo: en EE.UU., Alemania, Inglaterra ha habido un resurgimiento importantísimo de la inteligencia artificial a partir de los ‘programas expertos’ y con ellos florece toda una industria, aparecen montones de empresas que fabrican hardware especializado para sistemas expertos como las ‘Lisp machines’. Por ejemplo los congresos de AI de Chicago en 1995 y en Los Ángeles 1987 hay como 6.000 participantes en cada uno. Así que, tras el invierno anterior llegó la nueva primavera de la inteligencia artificial. Luego se ha ido manteniendo bien a nivel de financiación. Pero últimamente lo nuestro, la AI vuelve a estar muy de moda. Llevamos uno o dos años que hay un ‘hype’ de la Inteligencia Artificial que entre cantidad de películas que están tratando el tema han surgido incluso multitud de debates. Hay ahora un resurgimiento de la AI.
Parte IV. SOBRE LA AI APLICADA:
A.P.: Hablemos ahora de la ‘AI’ aplicada. ¿Crees que ha cambiado el rumbo de la Ciencia de la Inteligencia Artificial el que haya ‘girado la esquina’ la industria informática, pasando a lo que Steve Jobs ya llamó ‘la Era PostPC’, a la era de los Data Center que contienen gigantescas granjas de servidores, capaces de poner a disposición de la gente aplicaciones que tienen detrás una enorme capacidad de computación que esta oculta tras ellas? ¿Esta emergiendo, en este cambio de paradigma de la informática, una AI distinta a la que habías imaginado hace una década cuando los científicos de la disciplina pensabais cómo seria el próximo futuro de esta ciencia?
R.L.M.: Sí, así es. Ha cambiado mucho. Nosotros pensábamos la década pasada que la Inteligencia Artificial seguiría el camino este de intentar hacer la AI con bases cognitivas o plausible cognitivamente. De nuevo, como en la pregunta anterior, pensábamos que avanzaríamos imitando al cerebro a nivel macroscópico, es decir había que avanzar inspirándose mucho en la inteligencia humana, a alto nivel cognitivo. Imitando la forma de razonar, aprender de humana a un nivel de sistema. Entonces, lo que ha sorprendido a mucha gente en estos últimos años se es lo que esta consiguiendo en ejemplos como Watson, lo del Google Traslator, lo de Siri de Apple, que se basan en técnicas, práctica y puramente estadísticas de análisis de gran cantidad de datos, de buscar relaciones y correlaciones entre datos que dan unos resultados prácticos muy buenos, muy interesantes, pero sin olvidarse completamente de lo que es la cognición humana. El superordenador Watson, (que ganó a dos humanos muy especializados en el concurso de televisión estadounidense Jeopardy! ), no entiende ni una sola palabra de las preguntas qué le hacen y, sin embargo, las responde correctamente. ¿cómo puedes responder a una pregunta de la que no entiendes nada semánticamente? Watson no entiende semánticamente nada del significado de las preguntas que le hacen. Hace ‘contaje’ de las frecuencias y proximidad con que aparecen esos términos en millones de documentos (a grandísima velocidad) y de ahí consigue dar respuestas que son correctas en la inmensa mayoría de los casos.
A.P.: O sea que responde correctamente sin entender nada, ni siquiera de sus respuestas ni tener conciencia de ello.
R.L.M.: No, no. Ni conciencia ni capacidad de comprender el lenguaje. Es un proceso de pregunta-respuesta, que funciona. Te voy a explicar un ejemplo para que se entienda bien. En el concurso Jeopardy! Contra dos seres humanos a los que venció, una pregunta que respondió Watson fue la siguiente: “El nombre de este sombrero es elemental, querido concursante”. Y Watson respondió de inmediato que era el sobrero de cazador. ¿porqué? Pues porque encontró que la frase “Elemental, querido…, aparecía en muchas novelas de Sherlock Holmes, y en miles y miles de documentos, no en las mismas páginas sino en muchas otras de los mismo documentos aparecía el nombre de un sombrero cuando se describía el aspecto de Sherlock Holmes que llevaba un sombrero de cazador. Al encontrar esta correlación tan alta entre la frase de elemental querido” con la descripción de una sombrero, el ordenador Watson está programado para encontrar estas concurrencias de términos, dio la respuesta, “sombrero de caza”, que es la respuesta correcta, pero que él no sabe lo que significa. Watson no sabe lo que es un sombrero, ni lo que es ‘elemental’. No sabe nada. No entiende la semántica del lenguaje. Esto es muy sorprendente y sorprendió a mucha gente el que Watson fuera tan bueno respondiendo preguntas, cuando todos en el mundo de la AI sabíamos o sabemos lo difícil que es para una máquina, para un ordenador, comprender el verdadero, significado profundo del lenguaje.
A.P.: Y sin embargo, para esto, funciona la fuerza bruta de computación.
R.L.M.: Sí, a nivel tan superficial sin conocer el lenguaje, funciona con fuerza bruta, con mucha mucha computación.
A.P.: ¿Es la Inteligencia Artificial de la Era de Internet distinta a la de la época de los Robots ‘arácnidos’ del MIT CSAIL con inteligencia artificial por capas, como Hannibal o Attila que aprendían cada vez a andar desde cero; o como Herbert o Allen, el primer robo móvil, o como Cog o Kismet los robots con aspecto e inteligencia humanoide capaces de interactuar e imitar a los humanos?. ¿Que tienen en común y que diferencias hay entre la AI pre-Internet, y la actual de la época del Internet global?
R.L.M.: Sí, claro. Hay mucha diferencia. Internet es, en el fondo como una gran base de conocimientos y hay una nueva tendencia que se llama la ‘Cloud-robotics’ en donde cada robot aprende mucha mas rápidamente, porque no esta aislado sino que a través del ‘Cloud’ (La Nube) y de Internet puede tener acceso a información. Y lo que aprende un robot lo puede aprovechar otro robot que está relacionado con el primer robot a través del Cloud o a través de Internet. Hay una aplicación muy divertida en robótica que es un robot que mira un objeto: No lo puede reconocer, y entonces saca una foto del objeto que está viendo, sube la foto a Internet y usando mecanismo como el del Mechancial Turk que usa también Amazon y es muy probable que de forma colaborativa alguien etiquete la imagen semánticamente y añada una etiqueta (un ‘tag’), por ejemplo: “florero”, no sé, “bicicleta”, lo que sea, ye entonces, el robot ya recibe este ‘tag’ y ha conseguido que le digan qué es aquello que esta mirando y que no sabe lo que es. Esto, en la era pre-Internet era imposible. Entonces, un robot era una cosa aislada completamente que, o tenía los recursos dentro de él, en su memoria, en su sistema, o no podía preguntar, Bueno podía hacerlo a su programador pero estaba aislado y no podía resolver por sí solo su pregunta como sí lo hacen ahora-. Ahora, estas cosas cambian completamente gracias a internet, o sea que la diferencia es enorme.
Parte V. SOBRE APLICACIONES PRÁCTICAS Y EMPRESARIALES DE LA AI. LOS AGENTES INTELIGENTES:
A.P.: Los Agentes de AI son una pieza fundamental de la gigantesca cibernética que circula y actúa en las redes y en Internet hoy en día: son capaces de realizar miles de ‘negociar’ transacciones por segundo en la Bolsa (es ocurre cada día en la High-Frequency Trading. HFT), cosa imposible para un humano; también son capaces de negociar entre muchas ofertas, comparando y eligiendo la mas rentable. Tengo varias preguntas, de nuevo: ¿Eso no esta muy cerca de lo que serían máquinas (de software) tomando decisiones autónomas? ¿Que diferencia hay entre la negociación entre humanos en comparación con la negociación entre AI Agents?
R.L.M.: Sí, los AI Agents, o ‘agentes inteligentes’ de software toman decisiones autónomas en la Bolsa. Y ha habido crahses de la bolsa cuyos culpables han sido estos agentes que toman decisiones y compren o venden acciones en milisegundos. A ver, no es que negocien nada. No hacen un diálogo con argumentos con nadie, estos ‘agentes-programas de software’. Toman decisiones así, ellos solitos sin negociar con nadie.
A.P.: Pero hacen operaciones de bolsa que duran nanosegundos, algo imposible para un humano.
R.L.M.: Ahí no hay negociación posible. El software compra y vende y punto. Y en base a su programación.
A.P.:¿Y eso es rentable?.
R.L.M.: Bueno, sí claro, pero también ha provocado problemas en la bolsa. Hubo un crash enorme en la bolsa por esta causa. Para mi esto es algo pernicioso. Debería estar prohibido completamente. Habría que quitar estos agentes autónomos de la bolsa y el mercado bursátil. ¿Porqué tenemos en Internet Captchas y todo eso en Internet? Pues para evitar que esto agentes automáticos hagan cosas que nos engañan. ¿Y porqué se permite que estos agentes compren y vendan acciones en el mercado electrónico de la bolsa? Pues no sé. Yo creo que es una burrada que actúen estos agentes autónomos, que son completamente autónomos y que, por tanto, que escapan a nuestro control. Yo creo que siempre debe haber un control. Siempre hemos de tener un control sobre las máquinas, sean físicas o de software. Yo, la autonomía plena, la prohibiría completamente, dentro de la inteligencia artificial.
 Ramón López de Mántaras, director del IIIA-CSIC. Foto: Adolfo Plasencia
Ramón López de Mántaras, director del IIIA-CSIC. Foto: Adolfo Plasencia
A.P.: ¿O sea, tú estas contra de que se use la inteligencia artificial para la High-Frequency Trading (HFT), o Negociación de Alta Frecuencia.
R.L.M.: Absolutamente. Habría que prohibir drásticamente que esto, (el HFT), funcione en las bolsas. Están causando muchos muchos perjuicios. Están proporcionando mucho dinero a unos cuantos, pero están perjudicando a la sociedad. A.P.: ¿Cómo se entiende la Innovación en tu disciplina? ¿Se entiende normalmente como algo incremental, o la verdadera innovación en AI emerge cuando hay un cambio disruptivo?
R.L.M.: En general, en ciencia no creo demasiado en la disrupción. La ciencia progresa incrementalmente y te vas apoyando incrementalmente en lo que otros han conseguido, haces mejoras en lo que otros han hecho y los otros, tus peers, tus iguales, mejoran lo tuyo. Es un progreso mas o menos lineal. No creo en la exponencialidad del progreso de la técnica y la tecnología. Esto es falso. No progresan exponencialmente.
A.P.: ¿Entonces no estarás de acuerdo con el argumento de la ‘Singularidad esta cerca’ de Kurzweil, verdad?
R.L.M.: Estoy en total desacuerdo con él. Entre los años 60 y los 80 hubo mas progresos en AI que entre los 80 y 2000. Se ha ido progresando pero linealmente, no exponencialmente. En inteligencia artificial, disruptivo no ha habido nada. Y dudo que algún día haya algo realmente disruptivo y en otras ciencias tampoco. También me puedo equivocar pero lo mas probablemente es que todo vaya cambiando incrementalmente.
Parte VI. SOBRE APLICACIONES INTELIGENCIA ARTIFICIAL E INNOVACIÓN. MACHINE LEARNING Y DEEP LEARNING
A.P.: te he visto participar ya en dos Jornadas sobre Machine Learning. Sobre el Aprendizaje Automático y el Deep Learning basado en Inteligencia Artificial, se dice que se pueden aplicar, combinado con el Big Data a casi todos los sectores de negocio tanto para análisis y gestión de producción y mercados como para predecir el comportamiento o evolución futura, desde el comercio hasta las enfermedades. Estos términos están en todos los medios, en las noticias, por todos lados. ¿No hay una cierta ‘burbuja’ sobre las virtudes del Machine Learning y de sus aplicaciones?
R.L.M.: Yo creo que es cierto que el Machine Learning (Aprendizaje automático) y el Deep Learning (aprendizaje profundo) por la capacidad actual de procesar con gran rapidez cantidades masivas de datos ha permitido progresos importantes, siempre incrementales, sin ser disruptivos. En cuanto a la aplicaciones de la Inteligencia Artificial para tomar mejores decisiones en todos estos ámbitos empresariales que has mencionado y otros, yo pienso que eso es cierto. Bueno, es inevitable que venga acompañado de una cierta burbuja, de un cierto ‘hype’. Parece que ahora esta muy de moda el término. Da la impresión de que si estás trabajando en Machine Learning y no haces Deep Learning, no estás haciendo nada. Aun se pueden hacer aportaciones en ideas básicas en el primero sin entrar en el segundo. Todas las ideas que están aplicándose en el Deep Learning son de hace diez o quince años. No hay ahora conceptualmente nada nuevo en este campo ahora mismo.
A.P.: Pero es que lo que se está diciendo es que sirve para todo tipo de sectores y empresas.
R.L.M.: Yo creo que sirve para muchísimas cosas. Porque es muy común que en muchos sectores, -mientras haya grandes cantidades de datos que manejar, si no, no-, en donde puedes detectar patrones, tendencias, comportamientos, etc., desde cualquier sector económico hasta los de la salud, pasando por todo lo que te puedas imaginar. La verdad es que se ha abierto y hay un potencial de aplicación brutal.
A.P.: Cuando la gente usa Siri, el asistente personal que Apple ha puesto disponible (si tiene buen ancho de banda) en su iPhone, en su inmensa mayoría no sabe que al otro lado. Al otro de Siri, hay enormes granjas de servidores con una inmensa capacidad de computación e inteligencia artificial, que es lo que hacen que Siri le hable y contesta a sus preguntas de modo ubicuo, es decir en cualquier momento y lugar. La gente lo usa cómodamente en su vida cotidiana pero ni se imagina todo esto ¿No crees?
R.L.M.: es verdad que no lo sabe y no lo pensamos.
A.P.: Pero si ha AI ha llegado aparentemente tan fácilmente a nuestra vida cotidiana, el paso siguiente podría ser que la Inteligencia artificial que hasta ahora era algo propio de grandes corporaciones y empresa globales, también llegue pronto a las pequeñas y medianas empresa para que lo usen en sus negocios, ¿Ese seria el siguiente paso de la AI en las empresas? ¿El que una Pyme puede usar la inteligencia artificial en su actividad cotidiana?
R.L.M.: Sí, claro que es posible y puede ser. Eso esta cercano. Mira lo que hace la misma BigML que tiene su centro de desarrollo en Valencia, en España. Tú ya no tienes que tener los servidores y la gran capacidad de cálculo que hay detrás de la AI. Es el Sofware As A Service (Software como Servicio), el software en tanto que servicio. Por usar una comparación, es como al agua corriente. Abres el grifo y tú consume la cantidad de agua que necesitas hasta que cierras el grifo, igual que la cantidad de electricidad del contador de tu empresa. Ahí puede tener tus datos, mayor o menor en función de la actividad de la empresa; cargar estos datos en la plataforma de Big ML y sacar partido de toda esta tecnología basada en AI desde tu empresa y para tu empresa de una forma poco costosa.
A.P.: Un poco las pequeñas empresas como ‘usuarios casuales’ de la AI y sus aplicaciones para las empresas.
R.L.M.: Sí, claro es un uso muy transparente. El usuario, la empresa, no tiene porqué saber cómo funciona los algoritmos de aprendizaje profundo, ni nada. Una empresa puede ser, sí, usuario casual o permanente o usarlo en parte cada día, como quien abre el grifo cada día o como quien conecta la electricidad cada día como te he dicho. El SaaS es un concepto muy interesante.
Parte VII. LA POLEMICA DE LA ‘AMENAZA DE LA AI
A.P.: En relación a la AI, también hay quien vislumbra amenazas. A pesar de que Rodney Brooks publicó en noviembre pasado un artículo llamado “La inteligencia artificial es una herramienta, no una amenaza“, Stephen Hawking ha afirmado en la BBC que “El desarrollo completo de la inteligencia artificial podría significar el fin de la raza humana.” Imagino que sabrás sobre La polémica sobre la Ética de los Robots y la posible (probable para algunos) ‘amenaza’ de la AI encarnada sobre todo en forma de ‘Armas Letales Autónomas’. Dicho debate se ha multiplicado cuando nombres de mucha importancia de la tecnología como Elon Musk, CEO de Tesla, o Steven Wozniak co-fundador de Apple, junto a miles de investigadores de todo el mundo (entre ellos alguno de vuestro IIIA), han suscrito la ‘Carta Abierta del Instituto para el Futuro de la Vida’, titulada “Research Priorities for Robust and Beneficial Artificial Intelligence” en la que marcan ‘prioridades’ de investigación para la AI. ¿Crees que pueden, aplicaciones de la AI, como las armas letales autónomas’, convertirse en una Amenaza para la humanidad como aseguran algunas figuras relevantes del mundo tecnológico? ¿Crees que al investigación en AI debe ‘auto-inhibirse’ en relación a su futuro? ¿Cuál es tu posición al respecto como científico?
R.L.M.: Actualmente, la Inteligencia Artificial, mas que como amenaza ya hay que tener en cuenta que viene aplicándose con una serie de problemáticas y riesgos. Las armas autónomas son ya una amenaza muy real, desde luego que sí. Se está trabajando en ello, por ejemplo en EE.UU., construyendo robots-soldad, drones con capacidades autónomas para disparar o no, sin que un ser humano intervenga en esa decisión. Esta es una amenaza muy real. O la de la privacidad: la verdad es que la estas tecnologías han contribuido a que ya no tengamos vida privada, actualmente. Todo esto no es que sea una amenaza, es que ya está aquí. Yo pienso que sí, que hay que poner limitaciones. Algunos investigadores sí nos oponemos. En mi instituto nos negamos absolutamente a trabajar en prontos militares de robots soldados, etc. No vamos a hacer nada de todo eso. La comunidad es libre. Hay cantidad de mis colegas que están trabando en temas militares, sin ningún problema de conciencia. A mí me sabe mal pero no puedo hacer nada. Mi posición es clarísimamente en contra. Lo que estamos intentando algunos es que la ONU haga una resolución igual que hizo con las armas química y bacteriológicas. Ya hicieron una resolución en contra de las ‘Lethal autonomous weapon’ (Armas letales autónomas), pero siempre habrá mercados negros y gente que las fabrique. Hay muchos interese económicos y la industria del armamento es un lobby muy potente. Por mucho que algunos protestemos, inevitablemente y desgraciadamente, acabará habiendo armas autónomos. Estamos haciendo cosas… en la humanidad se están también haciendo cosas completamente locas, guiados por la única ambición y avaricia del dinero y esto pasa por encima de cualquier consideración ética. Pero bueno, tenemos derecho al pataleo, a llamar la atención a la opinión pública y a lo mejor sí, si una gran mayoría se pone en contra, igual podemos frenar algo esto. Pero en algún lugar acabarán apareciendo.
Parte VIII. SOBRE EL IIIA (Instituto de Inteligencia Artificial del CSIC).
En el IIIA (Instituto de Inteligencia Artificial del CSIC), que tú diriges, mantenéis tres líneas principales de investigación: la lógica, el razonamiento y la búsqueda; El razonamiento y el aprendizaje basado en casos; y los agentes y sistemas multi-agente inteligente. Estas líneas de investigación se aplican a muchos ámbitos comerciales y de negocios como los mercados electrónicos, las ‘tecnologías de acuerdo’, la medicina, la música, la información de privacidad / seguridad y robots autónomos. ¿Puedes describirnos vuestras actividades investigadoras? ¿Como es vuestra relación con el tejido empresarial, con que tipo de empresas colaboráis y cómo son los tipos de aplicación práctica ahora mismo en el mundo de la empresa?
R.L.M.: Estamos colaborando todo tipo de sectores, desde el sector salud hasta el de logística y transporte o turismo, en todos esos ámbitos que has mencionado. La inteligencia artificial es que es aplicable a todo. Es aplicable prácticamente al 100% de cosas. No hay nada en lo que la AI no pueda ser útil. Hemos trabajado en todos estos sectores que te he mencionado, hasta en entretenimiento o la TV, para resúmenes automáticos de partidos de fútbol, o en Fórmula 1, por ejemplo. Tenemos una unidad de transferencia de tecnología que coordina toda nuestra actividad con empresas y sectores.
A.P.: Entonces eres optimista.
R.L.M.: Soy optimista para esta Inteligencia Artificial que es útil, socialmente responsable, funciona muy bien y nos ha servido para hacer hasta cuatro empresas spin-off que han creado entre 100 y 150 puestos de trabajo de alta cualificación. Tenemos una muy buena experiencia de transferencia de tecnología en nuestra actividad compartida con empresas.
A.P.: Muchas gracias, Ramón.
R.L.M.: Gracias a ti.
……………..
Publiqué una síntesis de esta conversación con Ramón López de Mántaras en el Suplemento INNOVADORES de El Mundo, con el título: “Deben prohibir los robots con inteligencia artificial en Bolsa”








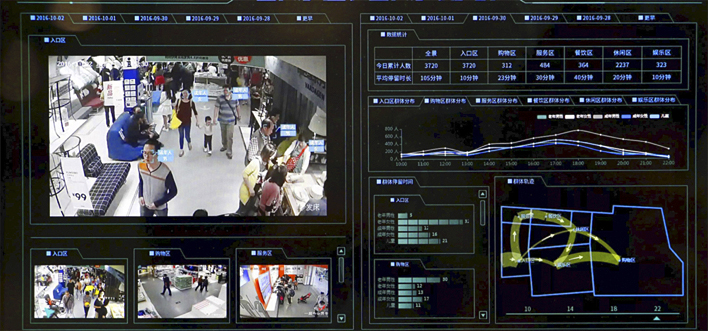 Interfaz del software de ‘Sourveillance’ con IA de la empresa china SenseTime, que reconoce las caras, graba los patrones movimientos de las personas, en una tienda de Pekín, y los procesa estadísticamente para vigilar y predecir sus movimientos futuros. Ningún visitante de la tienda, lo puede evitar.
Interfaz del software de ‘Sourveillance’ con IA de la empresa china SenseTime, que reconoce las caras, graba los patrones movimientos de las personas, en una tienda de Pekín, y los procesa estadísticamente para vigilar y predecir sus movimientos futuros. Ningún visitante de la tienda, lo puede evitar.


 Pondré algún ejemplo. Uno de los participantes es
Pondré algún ejemplo. Uno de los participantes es 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}